欢迎关注我的微信公众号【万能的小江江】
视频教程来自:https://www.bilibili.com/video/BV1hB4y1w7tZ
多进程概述
什么是forking
- fork(分岔)在Linux系统中使用非常广泛
- 某一命令执行的时候,父进程(当前进程)会fork出一个子进程
- 父进程会把自身的资源拷贝一份,命令在子进程中运行的时候,就具有和父进程完全一样的运行环境
例子
父进程工作目录切换
我们
vim chdir.sh创建一个改变目录的脚本#!/bin/bash cd /home先用bash运行:
bash chdir.sh,此时会发现工作目录并没有改变再用./运行:
./ chdir.sh,发现工作目录也没有改变(这个需要chmod +x chdir.sh添加执行权限)为什么不切换呢?
我们执行脚本的时候,父进程会生成一个子进程。子进程会切换到home目录,但是脚本执行完成后,子进程会销毁,因此父进程工作目录不改变
用source运行:
source chdir.sh,此时工作目录改变。因为source不产生子进程,直接父进程工作目录就改变了用.运行:
. chdir.sh,工作目录改变。因为.是source的简化版本改变bash解释器为python,
vim chdir.sh修改脚本#!/root/mypy/bin/python cd /home先用bash运行:
bash chdir.sh,不会报错,因为已经指定用bash来解释脚本了再用./运行:
./ chdir.sh,此时就默认是python的解释器,会报错的!!
查看返回值
我们
vim a.sh创建一个赋值脚本#!/bin/bash name = tom用bash运行:
bash a.sh查看返回值:
echo $name,会发现返回值为空。因为执行的时候生成的子进程,子进程执行结束就没有了用source运行:
source a.sh查看返回值:
echo $name,返回值为tom
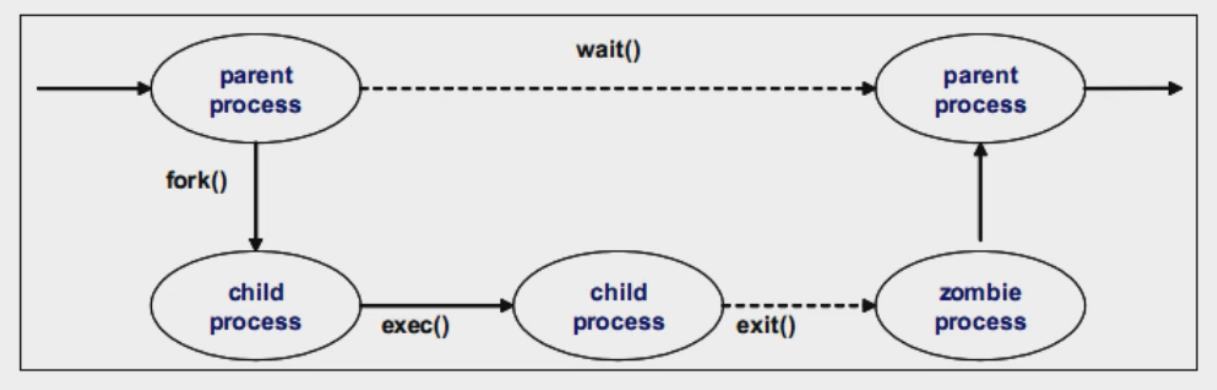
进程的生命周期
- 父进程fork出子进程并挂起
- 子进程运行完毕后,释放大部分资源并通知父进程。这个时候,子进程被称为僵尸进程
- 父进程获知子进程结束,子进程所有资源释放
例子
运行
gedit,打开记事本此时父进程被挂起,不能工作
运行
gedit &,子进程放到后台工作。父进程就还可以正常工作,未挂起
案例1:单进程、单线程ping
- 通过ping测试主机是否可到达
- 如果ping不同,不管是什么原因都认为主机不可用
- 需要通过ping的方式,扫描主机所在网段所有的IP地址
例子
新建python file:
ping.py去查下当前ip地址段是多少:
ifconfig或者ip a s=ip address showimport subprocess #导入subprocess模块 def ping(host): result = subprocess.run( 'ping -c2 %s &> /dev/null' % host,shell = True #ping -c2只发2个数据包,ping %s,有任何的输出&>,都把他屏蔽掉/dev/null,%s就是% host主机 ) if result.returncode == 0: #退出码为0就是成功了 print('%s:up' % host) else: print('%s:down' % host) if __name__ == '__main__': ips = ['192.168.113.%s' % i for i in range(1,255)] for ip in ips: ping(ip)用
python ping.py执行脚本,但是这样还是单进程一个一个执行就比较慢。可以用forking编程
forking编程的基本思路
- 需要使用os模块
- os.fork()函数实现forking功能
- python中,绝大多数的函数只返回1次,os.fork将返回2次(先在父进程运行一次,再在子进程运行一次)
- 对fork()的调用,如果是父进程会返回子进程的PID;对于子进程,返回PID0(判断真假)
案例2:forking基础应用
编写一个forking脚本
- 在父进程中打印”In parent”然后睡眠10s
- 在子进程中编写循环,循环5次,输出当前系统时间,每次循环结束后睡眠1s
- 父子进程结束后,分别打印”parent exit”和”child exit”
例子
使用fork创建子进程输出
import os
print('starting...')
ret_val = os.fork()
print('Hello World!')
#Result
starting
Hello World!
Hello World!
因为先执行一次父进程输出,再执行子进程s复现整个过程
import os
print('starting')
ret_val = os.fork()
if ret_val: #值非0为真
print('in parent')
else:
print('in child')
print('Done')
#Result
starting
in parent
Done
in child
Done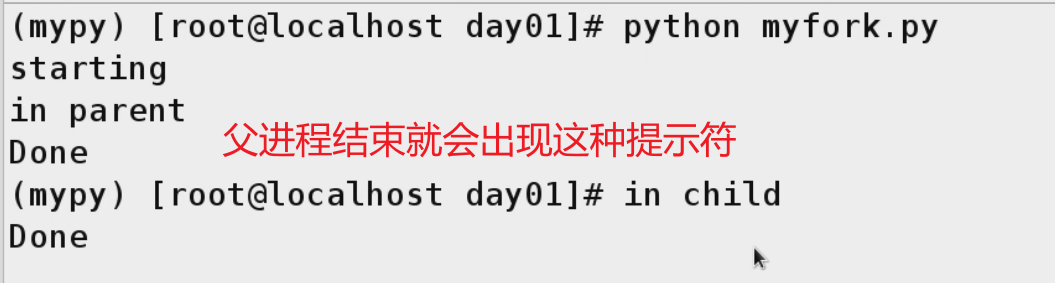
编写一个forking脚本
import os
import time
print(starting...)
ret_val = os.fork()
if ret_val:#如果ret_val为真,也就是说进入了父进程
print('parent')
time.sleep(10)
print('parent exit')
else:
print('child')
for i in range(1,6)
print(i)
time.sleep(1)
print('child exit')
#Result
parent
child
1
2
3
4
5
6
child exit
parent exit小结
- 多进程工作原理
- 多进程编程
多进程应用
多进程编程思路
- 父进程负责生成子进程
- 子进程做具体的工作
- 子进程结束后要彻底退出,否则可能会出现相关的问题
例子
fork子进程解析
import os
for i in range(3):
pid = os.fork()
if not pid:
print('hello')
#Result
会输出7个hello
hello
hello
hello
hello
hello
hello
hello为什么会输出7个hello呢
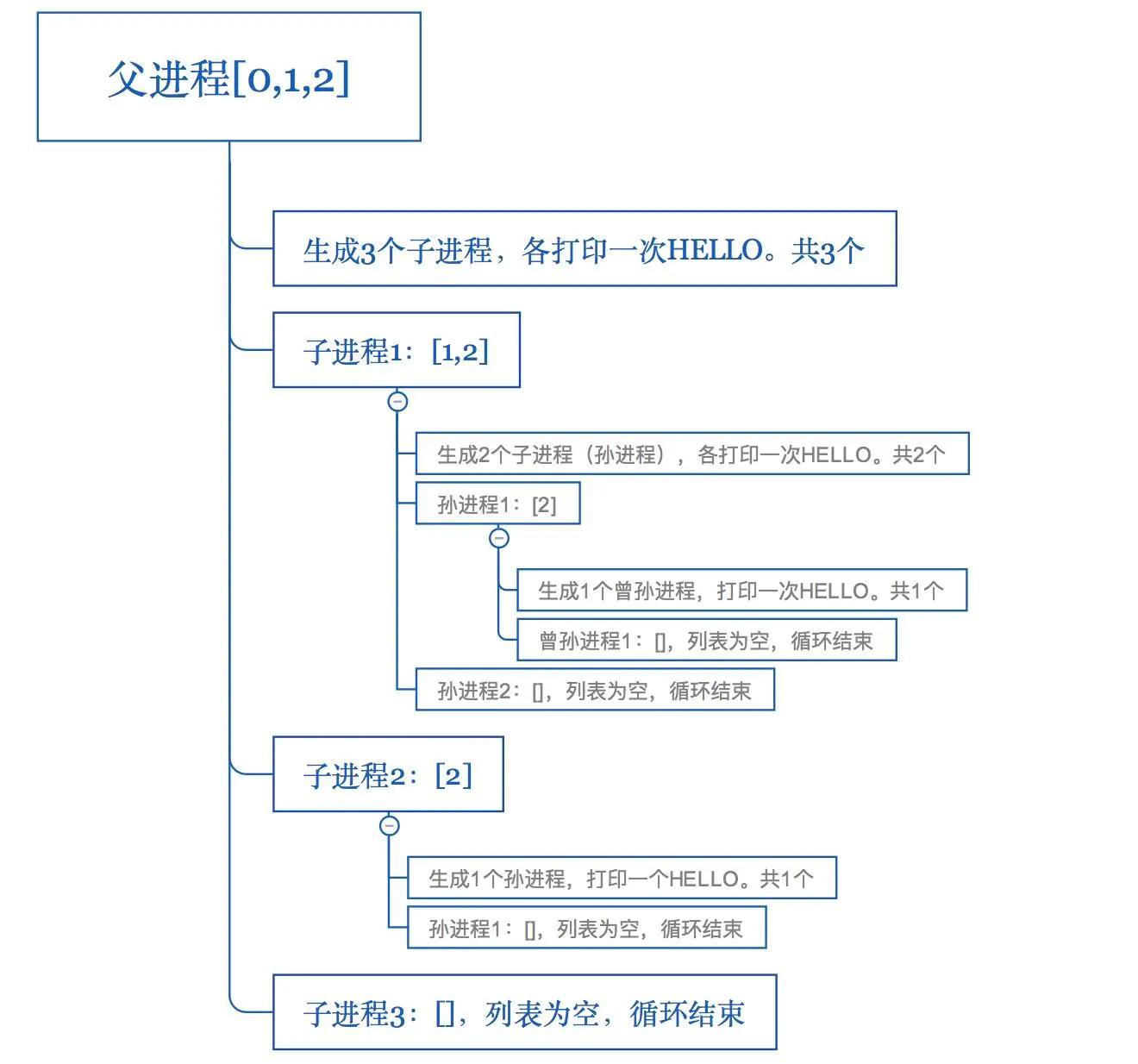
- 子进程还会生成它的子进程
例子
不及时退出子进程的后果
import os
print('starting')
for i in range(3):
ret_val = os.fork()
if not ret_val: #子进程ret_val是0,表示假,取反为真
print('Hello World!')
#Result
会输出7次Hello World!如何及时退出子进程
#在子进程结尾加个exit()就可以
import os
print('starting')
for i in range(3):
ret_val = os.fork()
if not ret_val: #子进程ret_val是0,表示假,取反为真
print('Hello World!')
exit() #进程遇到exit就会彻底结束
#Result
只输出3次Hello World!案例3:扫描存活主机(多进程)
- 通过ping测试主机是否可达
- 如果ping不通,不管是什么原因我们都当作主机down了,不可用
- 需要用ping的方式去扫描主机所在网段的所有IP地址
- 通过fork的方式实现并发扫描
例子
import os
import subprocess
def ping(host):
result = subprocess.run(
'ping -c2 %s &> /dev/null'%host,shell = True
)
if result.returncode == 0:
print('%s:up' % host)
else:
print('%s:down' % host)
if __name__ == '__main__':
ips = ['192.168.113.%s' %i for i in range(1,255)]
ret_val = os.fork()
for ip in ips:
if not ret_val:
ping(ip)
exit()僵尸进程
敲ps a命令的时候如果看到一堆僵尸进程就不太正常了,僵尸进程会消耗PID,开新进程没PID可用就会崩溃。所以需要去写处理僵尸进程的代码
- 子进程执行结束后没有可执行代码了就会变成僵尸进程,僵尸进程不能被调度
- 如果系统中存在过多的僵尸进程就会因为没有可用的进程号而导致系统不能产生新的进程
- 对于系统管理员来说,可用试图杀死其父进程或者通过重启系统来消除僵尸进程
解决zombie问题
- 父进程通过os.wait()来得到子进程是否终止的信息
- 在子进程终止和父进程调用wait()之间的这段时间,子进程被称为zombie(僵尸)进程
- 如果子进程还没有终止,父进程先退出了,那么子进程将会持续工作。系统自动将子进程的父进程设置为init进程,init将来负责清理僵尸进程
例子
每隔1s自动输入ps a
watch -n1 ps a
如何产生僵尸进程
import os
import time
print('starting')
ret_val = os.fork()
if ret_val:
print('in parent')
time.sleep(30)
print('exit zombie...')
print('parent exit')
else:
print('in child')
time.sleep(15)
print('child exit')
print('enter zombie...')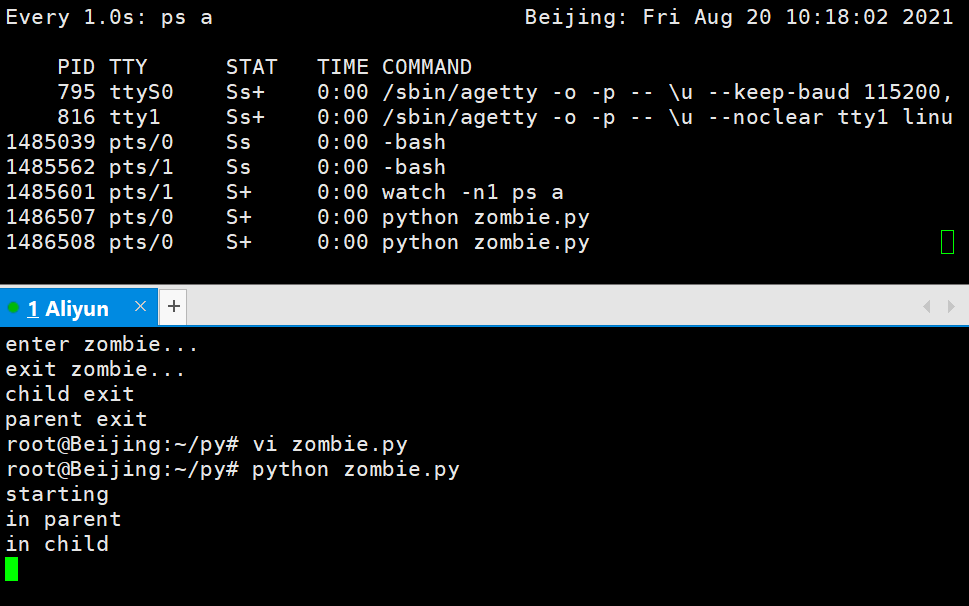
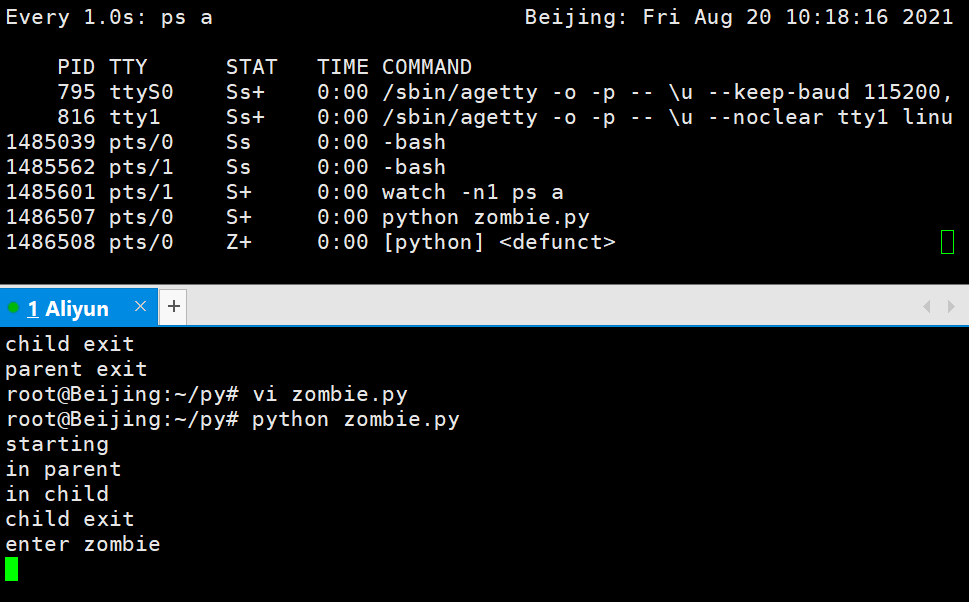
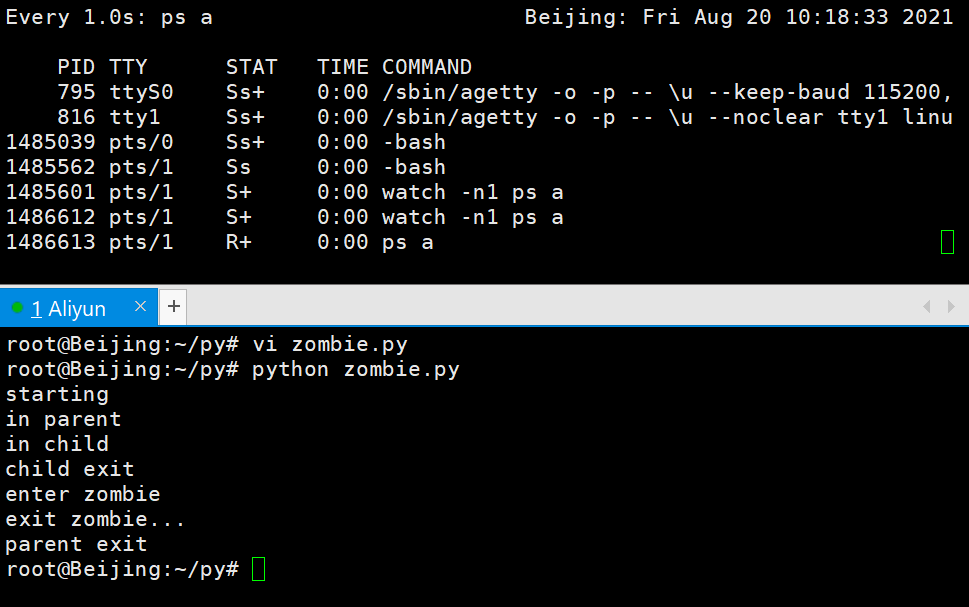
父进程结束,子进程还在
用pstree命令查看进程树,上帝进程是systemd一切进程的父进程,孤儿进程就会被systemd接管。孤儿进程的僵尸进程最终也会被上帝进程处理掉
import os
import time
print('starting')
ret_val = os.fork()
if ret_val:
print('in parent')
time.sleep(15)
print('parent exit')
else:
print('in child')
time.sleep(30)
print('child exit')杀掉僵尸进程
- 通过
kill 僵尸进程号去杀,发现杀不掉 kill -9 僵尸进程号强制杀进程,也杀不掉kill 父进程号直接杀父进程,子进程就会被systemd接管。systemd发现是僵尸进程就直接kill掉
解决zombie问题(续1)
python可以使用
os.waitpid()来处理子进程os.waitpid()接受两个参数,第一个参数设置为-1,表示与wait()函数相同;第二个参数如果设置为0,表示挂起父进程,只到子进程退出,设置为1表示不挂起父进程
os.waitpid(-1,0):与wait()函数相同,挂起父进程(不挂起就是继续向下执行)os.waitpid(-1,1):与wait()函数相同,不挂起父进程os.waitpid()的返回值:如果子进程未结束就返回0,否则返回子进程的PID
例子
判断子进程是否结束
import osimport time print('starting')ret_val = os.fork()if ret_val: print('in parent') result = os.waitpid(-1,0) print(result) #result是元组:(子进程pid,0),没有处理就返回(0,0) time.sleep(30) print(result) print('exit zombie...') print('parent exit')else: print('in child') time.sleep(15) print('child exit') print('enter zombie...')案例4:理解僵尸进程
- 通过代码了解僵尸进程
- 父进程和子进程同时进入睡眠
- 子进程结束睡眠,成为僵尸进程
- 父进程仍然处于睡眠状态一段时间,观察杀死子进程和父进程的结果
- 通过
os.waitpid()函数处理僵尸进程
小结
- 多进程编程思路
- 僵尸进程
多线程应用
多线程任务工作特点
- 这些任务本质上是异步的,需要有多个并发事务
- 各个事务的运行顺序可以是不确定的,随机的,不可预测的
- 这样的编程任务可以分成多个执行流,每个流都有一个要完成的目标
- 根据应用的不同,这些子任务可能都要计算出一个中间结果,用于合并得到最后的结果
什么是进程
- 程序就是磁盘中可执行的、二进制(或其他类型)的数据
- 进程(有时被称为重量级进程)是程序的一次执行
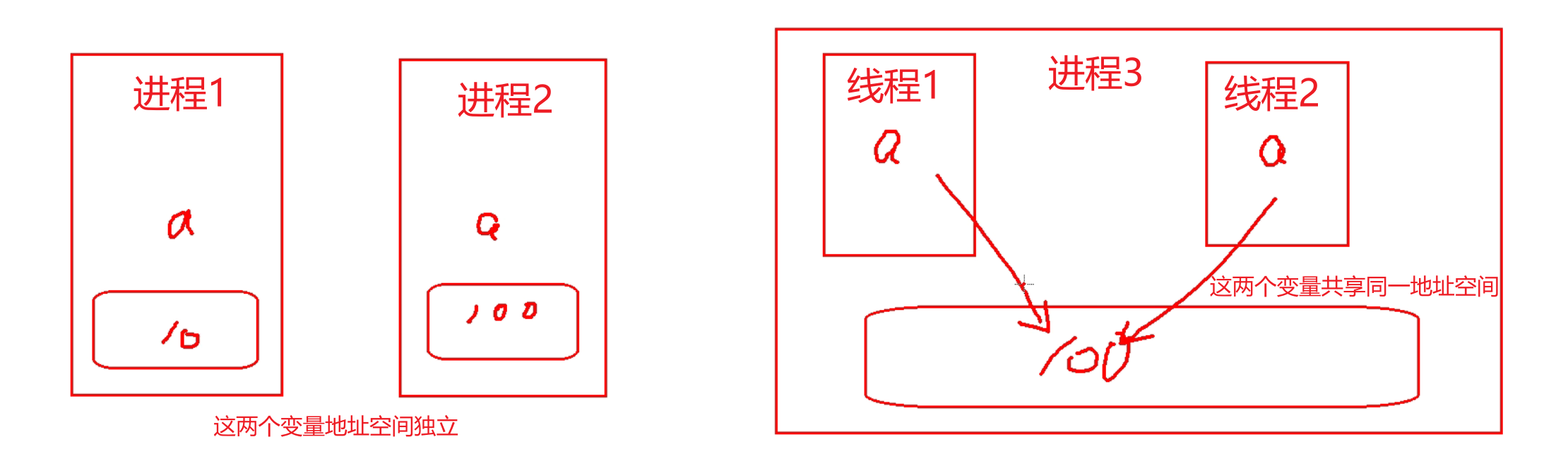
- 每个进程都有自己的地址空间、内存以及其他记录其运行轨迹的辅助数据
- 操作系统管理其上运行的所有进程,并为这些进程公平地分配时间
什么是线程
- 线程(有时候被称为轻量级进程)和进程有点类似。不同的是,所有的线程都运行在同一个进程中,共享相同的运行环境
- 一个进程中的各个线程之间共享同一片数据空间,所以线程之间可以比进程之间更方便地共享数据以及相互通讯
多线程编程
多线程相关模块
thread和threading模块允许程序员创建和管理线程thread模块提供了最基本的线程和锁的支持,而threading提供了更高级别、功能更强的线程管理功能- 推荐使用更高级别的
threading模块
传递函数给Thread类
- 多线程编程可以传函数给
threading模块的Thread类 - Thread对象使用
start()方法开始执行线程,使用join()方法挂起程序,直到线程结束
传递可调用类给Thread类
- 传递可调用类给Thread类
- 相对于一个或多个函数,类对象里面可以保存更多信息,有更强大的功能,使用这种方法传递会更灵活一些
案例5:扫描存活主机(多线程)
- 通过ping测试主机是否可到达
- 如果ping不同,不论什么原因都认为主机down不可用
- 通过多线程的方法实现并发扫描
例子
用线程输出HelloWorld
# 主线程只负责生成工作线程
# 工作线程负责做具体的工作
import threading
def say_hi():
print('Hello World!')
if __name__ == '__main__':
for i in range(3):
t = threading.Thread(target=say_hi) #创建工作线程
t.start() #启动工作线程 target()
#Result
Hello World!
Hello World!
Hello World!传参
# 主线程只负责生成工作线程
# 工作线程负责做具体的工作
import threading
def say_hi(word):
print('Hello %s!' % word)
if __name__ == '__main__':
for i in range(3):
t = threading.Thread(target=say_hi,args = ('tedu',)) #创建工作线程,tedu后面必须要加*才能成为元组,否则就是字符串(单元素元组就需要加,)
t.start() #启动工作线程 相对于target(*args)
#Result
Hello tedu!
Hello tedu!
Hello tedu!扫描存活主机
扫描存活主机(用类)
扫描存活主机(加init)
小结
Windows不支持多进程,只支持多线程
- 多线程工作原理
- 多线程编程
urlib应用
urllib基础
主要是用来编写一些与http、ftp相关的程序
urllib简介
urllib中包括了四个模块
urllib.request用来发送请求(request)以及获取request的结果urllib.error包含urllib.request产生的异常urllib.prase用来解析和处理URL(parse就是解析的意思)urllib.robotparse用来解析页面的robots.txt文件
爬取网页
- 先导入模块urllib.request
- 导入后,用urllib.request.urlopen打开并爬取网页
- 读取内容常见的3种方式:
- read()读取文件的全部内容,与readlines()不同,read()会把读取到的内容赋给一个字符串变量
- readlines()读取文件的全部内容,readlines()会把读取到的内容赋值给列表变量
- readline()读取文件的一行内容